Fetch, Upload, Organize, and Distribute Software Packages.
If you have to manage hundreds or thousands of packages, Pulp can help!
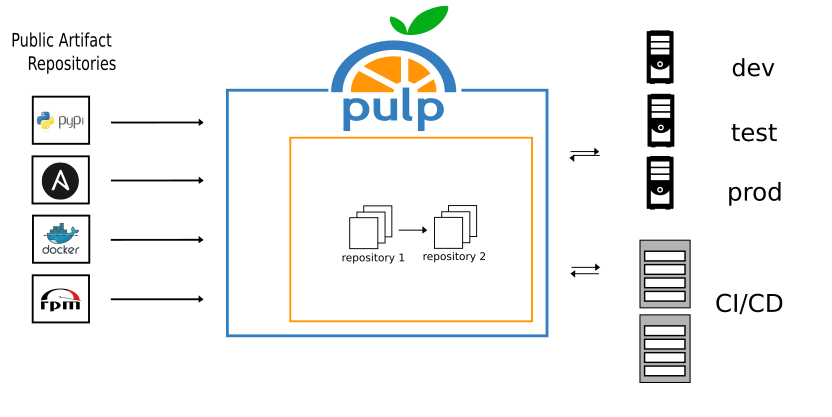
- Ensure stability and continuity: External content sources can go offline unexpectedly. If you want to ensure that you always have what you need, Pulp can help.
- Stop using rsync: Pulp is designed with complex content management workflows and disk optimization in mind. If your sync script is letting you down, Pulp can help.
- Reduce rate limiting: From one day to the next, third-party platforms can introduce rate limiting and change the conditions of service. If you want to reduce operation costs by having your team consume content from Pulp rather than third parties, Pulp can help.
- Distribute content privately: Sometimes you need a way to distribute private content you have developed in house. If you want to keep your private packages off third-party platforms and distribute them internally with ease, Pulp can help.
- Experiment without risk: Every change to content hosted in Pulp creates a new repository version. You can rollback to earlier versions whenever you need to. If you need to pin packages to certain versions to ensure stability and repeatability, Pulp can help.
… And much more!
Pulp is free and open-source, and we invite you to join us on GitHub.
Come chat to us on our community forum or on Matrix.
| What next? |
|---|
| New user? Start here |